
La técnica de Generación Aumentada por Recuperación (RAG) ha emergido como una herramienta potente para mejorar las capacidades de los grandes modelos de lenguaje (LLMs). Al combinar el vasto conocimiento almacenado en fuentes de datos externas con el poder generativo de los LLMs, RAG permite abordar tareas complejas que requieren tanto conocimiento como creatividad. Hoy en día, las técnicas RAG se utilizan en empresas de todas las escalas, donde la inteligencia artificial generativa se emplea para resolver preguntas basadas en documentos y otros tipos de análisis.
Aunque construir un sistema RAG simple es directo, desarrollar sistemas RAG de producción utilizando patrones avanzados representa un desafío. Una tubería RAG de producción opera típicamente sobre un mayor volumen de datos y con una mayor complejidad de datos, y debe cumplir con un estándar de calidad más alto en comparación con la construcción de una prueba de concepto. Un desafío general que enfrentan los desarrolladores es la baja calidad de respuesta; la tubería RAG no es capaz de responder adecuadamente a un gran número de preguntas, lo cual puede deberse a diversas razones, tales como:
- Recuperaciones incorrectas – Falta el contexto relevante necesario para responder a la pregunta.
- Respuestas incompletas – El contexto relevante está presente parcialmente, pero no completamente. La salida generada no responde completamente a la pregunta de entrada.
- Alucinaciones – El contexto relevante está presente, pero el modelo no es capaz de extraer la información relevante para responder la pregunta.
Esto requiere técnicas RAG más avanzadas en los componentes de comprensión de consulta, recuperación y generación para manejar estos modos de falla.
Aquí es donde entra LlamaIndex, una biblioteca de código abierto con técnicas tanto simples como avanzadas que permite a los desarrolladores construir tuberías RAG de producción. Proporciona un marco flexible y modular para construir y consultar índices de documentos, integrándose con varios LLMs e implementando patrones RAG avanzados.
Amazon Bedrock es un servicio gestionado que proporciona acceso a modelos fundacionales de alto rendimiento de proveedores líderes de inteligencia artificial a través de una API unificada. Ofrece una amplia gama de modelos grandes para elegir, junto con capacidades para construir y personalizar de forma segura aplicaciones de IA generativa. Las características avanzadas clave incluyen la personalización del modelo con ajuste fino y entrenamiento continuo utilizando sus propios datos, así como RAG para aumentar las salidas del modelo recuperando contexto de bases de conocimiento configuradas que contienen sus fuentes de datos privadas. Otras capacidades empresariales incluyen el rendimiento asegurado para inferencias de baja latencia a escala, evaluación del modelo para comparar el rendimiento y salvaguardas de IA para implementar medidas de seguridad.
En este artículo, exploramos cómo usar LlamaIndex para construir tuberías RAG avanzadas con Amazon Bedrock. Discutimos cómo configurar las siguientes:
- Tubería RAG simple – Configurar una tubería RAG en LlamaIndex con modelos de Amazon Bedrock y búsqueda vectorial top-k.
- Consulta de router – Añadir un router automatizado que pueda realizar dinámicamente búsquedas semánticas (top-k) o resúmenes sobre datos.
- Consulta de sub-preguntas – Añadir una capa de descomposición de consultas que pueda descomponer consultas complejas en múltiples más simples y ejecutarlas con las herramientas relevantes.
- RAG agencial – Construir un agente con estado que pueda realizar los componentes anteriores (uso de herramientas, descomposición de consultas), pero también mantener un historial de conversación y razonamiento a lo largo del tiempo.
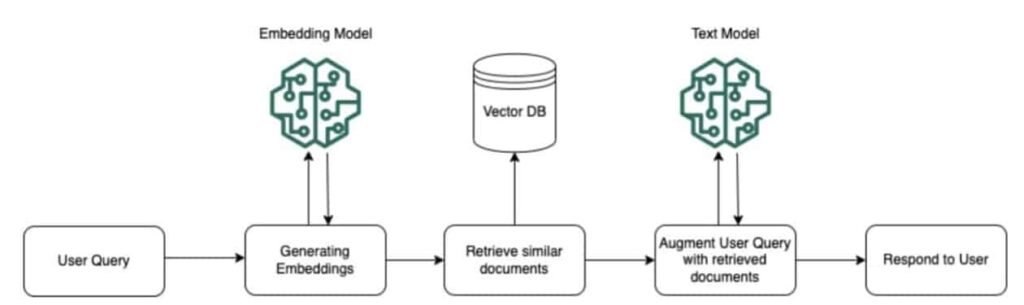
En su núcleo, RAG implica recuperar información relevante de fuentes de datos externas y usarla para aumentar las indicaciones que se alimentan a un LLM. Esto permite que el LLM genere respuestas fundamentadas en conocimientos factuales y adaptadas a la consulta específica. Para flujos de trabajo RAG en Amazon Bedrock, los documentos de bases de conocimiento configuradas pasan por un preprocesamiento, donde se dividen en fragmentos, se incrustan en vectores y se indexan en una base de datos vectorial. Esto permite la recuperación eficiente de información relevante en tiempo de ejecución. Cuando llega una consulta de usuario, el mismo modelo de incrustación se usa para convertir el texto de la consulta en una representación vectorial. Este vector de consulta se compara con los vectores de documentos indexados para identificar los fragmentos más similares semánticamente de la base de conocimiento. Estos fragmentos proporcionan contexto adicional relacionado con la consulta del usuario y se añaden a la indicación original del usuario antes de ser pasados al modelo fundacional para generar una respuesta.
LlamaCloud y LlamaParse representan los avances más recientes en el ecosistema de LlamaIndex, con LlamaCloud ofreciendo un conjunto completo de servicios gestionados para la augmentación de contexto a nivel empresarial y LlamaParse actuando como un motor de análisis especializado para documentos complejos. Estos servicios habilitan la gestión eficiente de volúmenes de datos de producción grandes, mejorando la calidad de las respuestas y desbloqueando capacidades sin precedentes en aplicaciones RAG.
Finalmente, la integración de Amazon Bedrock y LlamaIndex para construir una pila RAG avanzada se puede llevar a cabo siguiendo varios pasos precisos, desde la descarga de documentos fuente hasta la consulta final del índice con una pregunta específica. Esta avanzada configuración promete facilitar la gestión de grandes volúmenes de datos y mejorar significativamente la calidad de las respuestas generadas por los LLM en contextos complejos.
En conclusión, combinando las capacidades de LlamaIndex y Amazon Bedrock, las empresas pueden construir tuberías RAG robustas y sofisticadas que potencian al máximo los LLMs para tareas intensivas en conocimiento.
vía: AWS machine learning blog